Initié en 2020, le projet LiDAR HD porté par l’Institut Géographique National (IGN) vise à scanner le territoire français via LiDAR (Light Detection And Ranging), une technique de mesure de distance (télémétrie) qui exploite les propriétés de la lumière. En topographie, on utilise les données acquises par LiDAR (sous forme de nuages de points) pour produire des modèles numériques 3D représentatifs à la fois du sol et des éléments à la surface du sol tels que les bâtiments, les ouvrages d’art ou la végétation.
Dans le cadre du programme national LiDAR HD, l’IGN produit et diffuse une cartographie 3D de l’intégralité du sol et du sursol de la France en données LIDAR. Les données diffusées sont en particulier des nuages de points recalés, bruts ou classifiés, et des modélisations numériques 3D (MNT, MNS, MNH…).
1. Téléchargement de la parcelle en nuage de points
La carte des acquisitions du territoire français est disponible au lien suivant :
Une fois suffisamment zoomé sur le territoire, une grille fine bleue de 1 km x 1 km est visible sur le territoire français.
Dans la barre latérale de droite, trois outils existent pour sélectionner une emprise :
- Clic : Sélection dalle par dalle
- Polygone : Sélection en dessinant un polygone
- Rectangle : Sélection en dessinant un rectangle
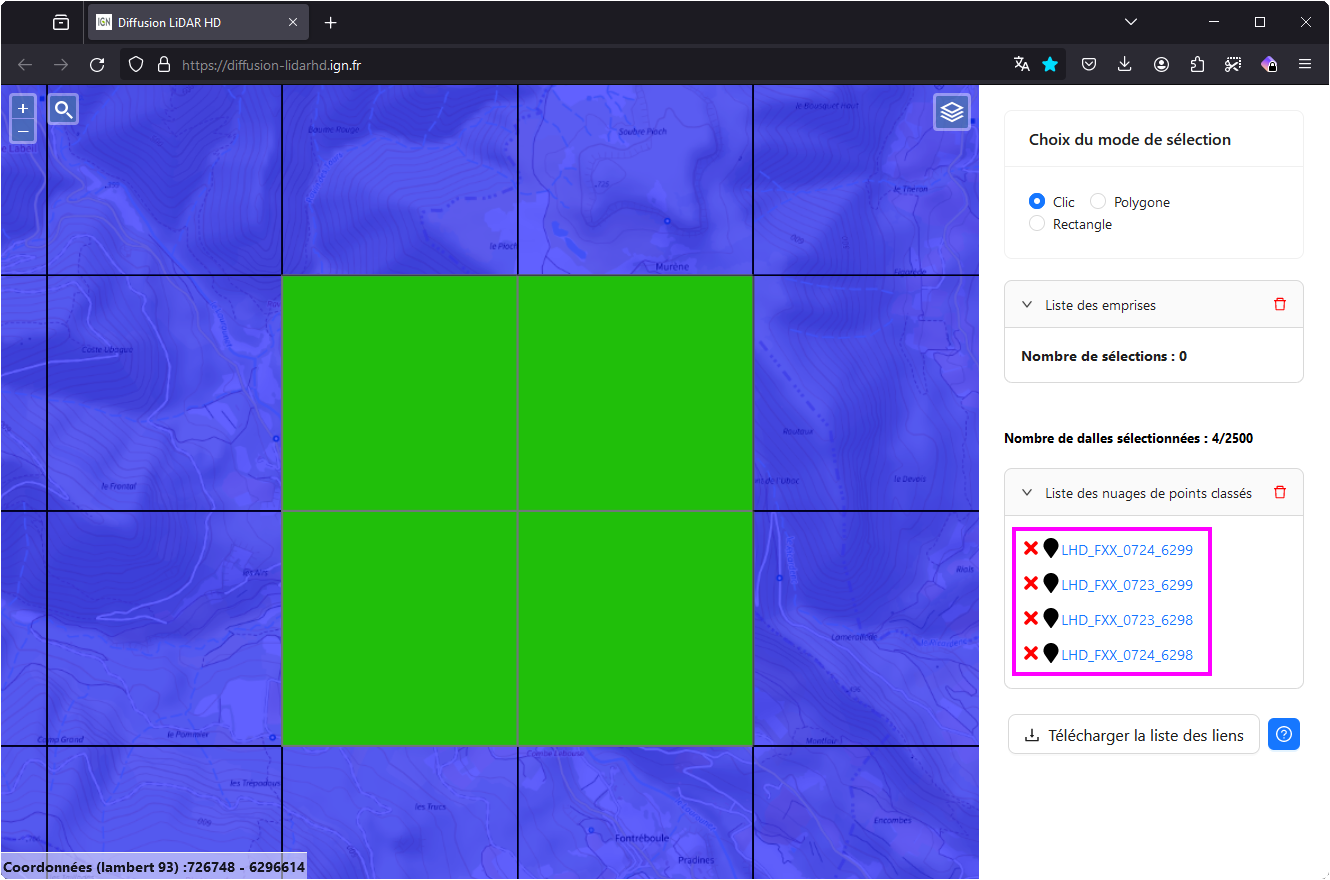
Une fois la ou les dalle(s) sélectionnée(s), les télécharger une par une en cliquant sur chacun des liens encadrés en magenta sur la capture d’écran ci-dessus.
2. Import du fichier .laz dans CloudCompare
Une fois la (ou les) dalle(s) téléchargée(s), il suffit de le(s) glisser-déposer dans le logiciel CloudCompare.
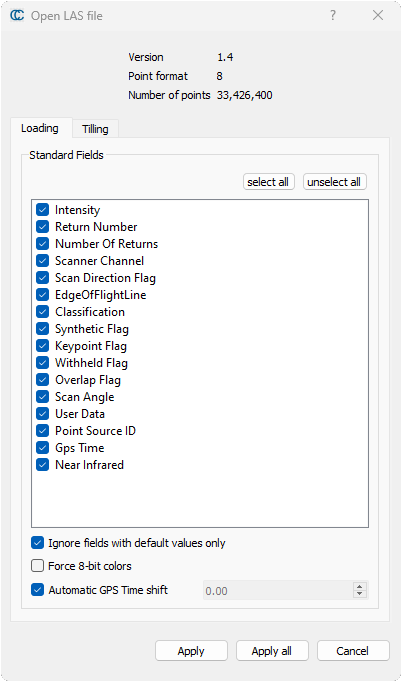
Une première fenêtre s’ouvre alors, “Open LAS File”, qui permet de sélectionner les informations à importer à l’ouverture du fichier. Cliquer sur Apply All.
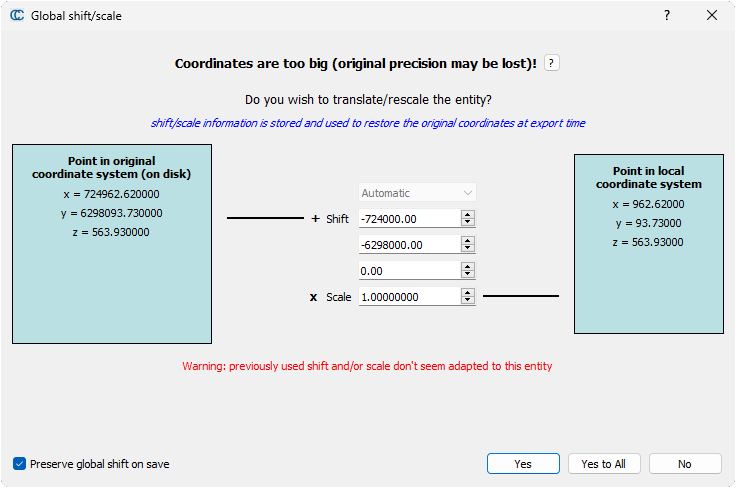
Une seconde fenêtre s’ouvre, “Global shift/scale”, permettant de spécifier une mise à l’échelle et un décalage des coordonnées. Il n’est à priori pas utile de changer quoi que ce soit. Simplement cliquer sur Yes to All.
Le(s) nuage(s) de points sont ensuite chargé(s). Ce processus peut prendre un petit moment selon la taille du (ou des) fichier(s).
3. Import dans CloudCompare et interface
L’interface de CloudCompare comporte plusieurs zones ici mises en évidence :
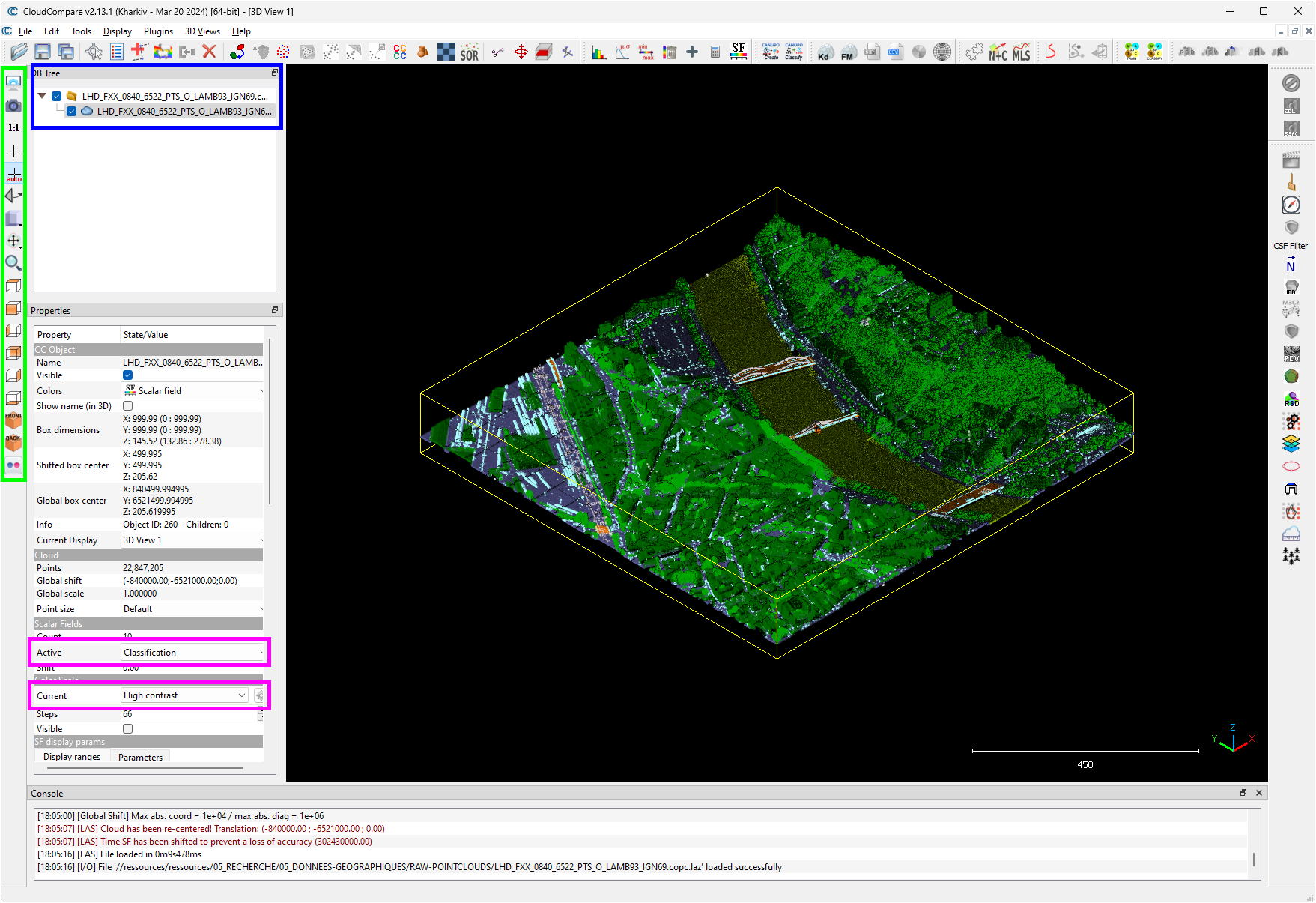
- En bleu : cette partie permet de lister les différents fichiers ouverts dans CloudCompare.
- En vert : les outils relatifs à l’affichage (vue perspective, vue orthographique, vue de dessus, etc).
- En magenta : choix du “Scalar Field” à afficher, c’est-à-dire du type de donnée. Dans ce menu déroulant, sélectionner le scalar field
Classification, qui contient la classification de points créée par l’IGN. En dessous, la “Color Scale” la plus à même de bien représenter la classification est laHigh Contrast, mais celle-ci a peu d’importance.
Il est impératif de sélectionner le scalar field
Classificationavant de procéder à la suite du traitement du nuage de point.
4. Traitement du fichier
4.1. Fusionner des nuages de points
Dans le cas où on souhaite travailler sur plusieurs nuages de points (lorsque la parcelle qui nous intéresse est au croisement de deux, trois ou quatre nuages de points), il est utile dans un premier temps de les fusionner.
Pour cela, sélectionner les nuages de points à fusionner dans l’arborescence :
Puis cliquer sur Edit > Merge. La fenêtre suivante s’ouvre :
Cliquer sur No, puisque nous n’exploiterons pas cette donnée par la suite.
Une fois cette action terminée, les nuages de points sont fusionnés, et prêts à être traités.
4.2. Filtrer les différentes classifications
La classification du nuage de point contient les éléments suivants :
| ID | Classification |
|---|---|
| 1 | Non classé (voitures, bruit, etc) |
| 2 | Sol |
| 3 | Végétation basse |
| 4 | Végétation moyenne |
| 5 | Végétation haute |
| 6 | Bâtiment |
| 9 | Eau |
| 17 | Tablier du pont |
Pour les filtrer et les isoler les uns par rapport aux autres, suivre la procédure suivante :
- Sélectionner le nuage de point.
- Cliquer sur
Edit > Scalar Fields > Filter By Value. - La fenêtre suivante s’ouvre, entrer le numéro de la classe à isoler (cf. tableau ci-dessus), par exemple pour isoler les bâtiments, on filtre de la valeur
6.0à la valeur6.0, puis cliquer surExport.

- CloudCompare créé alors un nouveau nuage de point dans l’arborescence, ne contenant que les bâtiments.
- Opérer de même pour chaque élément à isoler.
Pour isoler toute la végétation d'un coup, filtrer de la valeur
3.0à5.0.
4.3. Sous-échantillonage d’un nuage de points
Dans certains cas, il est utile de réduire la densité de points d’un nuage de points, pour éviter d’avoir un fichier trop gros à manipuler dans Rhino.
En effet, les fichiers d’origine de l’IGN ont une définition à 30 cm près, ce qui implique par exemple pour le fichier d’exemple ci-dessus un fichier contenant 33 millions de point pour une parcelle d’1 km².
Pour réduire la densité de points, sélectionner le nuage de points, cliquer sur Edit > Subsample. Une fenêtre “Cloud sub sampling” s’ouvre permettant de choisir les paramètres de réduction.
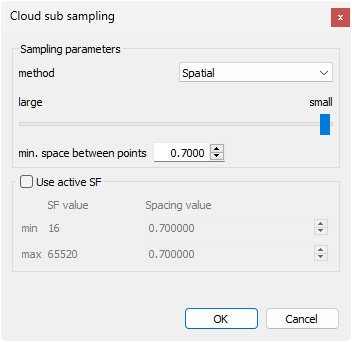
Le champ “min. space bewteen points” permet de définir l’espace minimal à conserver entre les points. Dans le cas présent, après plusieurs tests, la valeur 0.7 semble convenir pour réduire drastiquement le nombre de points tout en gardant une définition suffisante pour utiliser le nuage de points pour une modélisation de contexte (soit un point tous les 70 cm).
4.4. Génération d’un mesh à partir d’un nuage de points
Une fois le nuage de points du sol filtré, il est possible de générer un mesh représentant le terrain.
Selon la taille du nuage de points, il peut être utile de le sous-échantillonner avant d'essayer de créer un mesh.
Dans un premier temps, sélectionner le nuage de points représentant le sol, puis cliquer sur Edit > Normals > Compute. Laisser tous les paramètres par défaut, et cliquer sur OK. Le calcul des normales peut prendre un certain temps selon le nombre de points du nuage.
Une fois cette opération terminée, le nuage de point contient les normales calculées pour chaque point. En gardant ce nuage sélectionné, cliquer sur Plugins > PoissonRecon.
Le principal paramètre à entrer est la valeur de ‘Octree depth’. L’image ci-dessous permet d’apprécier le résultat selon la valeur entrée (entre 6, 8 ou 10).
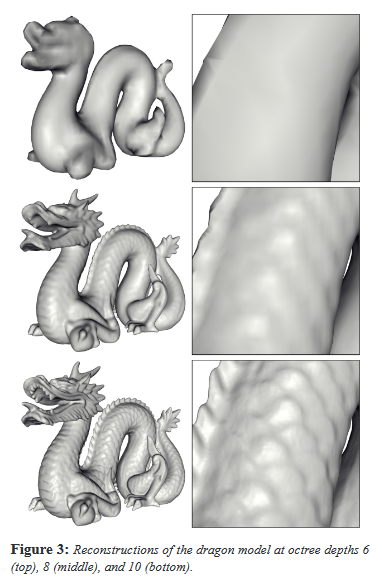
Il est important de noter que plus la valeur d' octree depth sera élevée, plus le temps de calcul sera long, et plus le mesh généré sera lourd et difficile à manipuler dans Rhino. Il est important de trouver ici un bon équilibre plutôt qu'une finesse maximale.
Une fois le mesh généré, suivre la procédure suivante pour l’importer dans Rhino, à l’exception du format de fichier, qui sera dans le cas d’un mesh .ply et non .txt. Rhino peut importer le format .ply sans problème.
5. Import dans Rhino
Une fois le nuage de point traité, et prêt à être exporté, sélectionner le nuage de points dasn Cloudcompare, et cliquer sur File > Save.
Le format à choisir est ASCII cloud (*.txt, *.asc, *.neu, *.zyx, *.pts, *.csv), pour créer un fichier .txt. Garder les paramètres d’export par défaut, et cliquer sur OK.
Une fois le fichier exporté (cela peut prendre un certain temps selon le nombre de points à exporter), ouvrir Rhino, et taper Import. Sélectionner le fichier .txt précedemment exporté, une fenêtre de paramètres d’import s’ouvre.
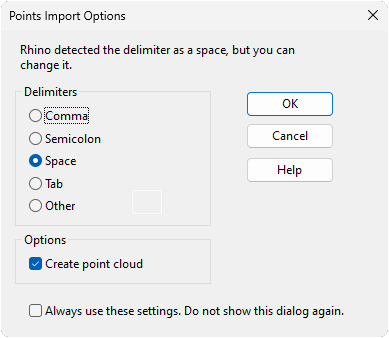
Il est important de cocher la case
Create point cloud, sans quoi les points sont tous importés comme des objets points. Le fait d'importer en tant qu'objet point cloud permet d'avoir un élément beaucoup plus léger à manipuler dans Rhino.
L’import peut prendre un certain temps selon le nombre de points. Une fois importé, le nuage n’est pas forcément visible dans le viewport, puisqu’il est importé avec des coordonnées qui lui sont propres. Simplement faire Zoom _Selected permet de cadrer la vue sur le nuage qui vient d’être importé (et qui est par défaut sélectionné.